
Orchestration Problem in Restaking
Cambrian as unifed gateway for Solana restaking and AVS orchestration


Staking in Proof-of-Stake (PoS) blockchains is a process in which participants, known as validators, deposit a certain amount of their cryptocurrency as collateral to support network operations such as validating transactions and securing the blockchain. This mechanism not only ensures the security of the network, but also incentivizes validators in the form of rewards. Staking is important because it aligns the interests of participants with the health and stability of the blockchain, promotes decentralization and makes attacks economically unfeasible.
Compared to staking, restaking introduced a third party to the PoS consensus — AVSes, increasing the number of actors in the process to more than two. And they all need to play in perfect harmony with each other to get the best out of the process. In music, even small orchestras need conductors to be in sync and sound glorious, and for CambrianOL's restaking, one such conductor will be. Let’s specify the problems that each of the parties has in the restaking, and try to find a unified modular way to solve them.
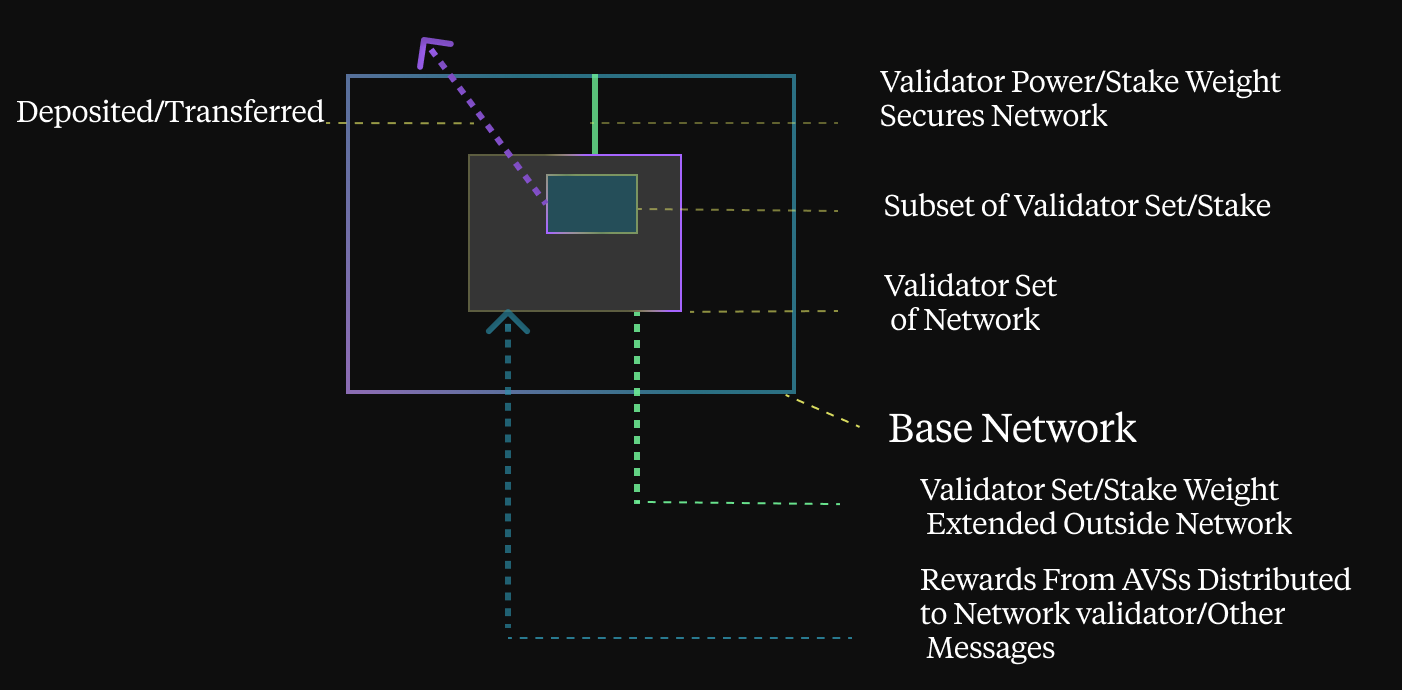
Let us first take a look at restakers. They want to optimize their stake according to one or more parameters, e.g. risk profile or return per stake, or they want to back specific nodes that perform certain tasks. All you can do now is either allocate your stake manually or use curated vaults such as those offered by mellow.finance. Either way, these solutions are not very dynamic and require a lot of attention, either from the person recovering them or from a vault curator (or both, if you want to switch vaults). Another obvious solution is Symbiotic, which also works with vaults as a coordination layer for restaking. Furthermore, the implementation of these solutions on Solana differs greatly from EVM-based solutions.
Next in line are AVSes. These have some flexibility in choosing the nodes on which they perform their tasks, but even these are not very dynamic. And what if there are not enough nodes in the restaking layer they were originally intended to run on? What if they want to dynamically change their requirements dynamically to accommodate workload or other factors? Again, this can not be done very efficiently because there simply are not the tools to do it.
And last but not least — worker nodes. This may look simple, but it's not really. Imagine you have set up your node, selected AVSes to run, set a stake on yourself or attracted another restaker’s stake, but your node is never selected for task execution. You can never know why, and that is really disappointing. Therefore, some statistics and simulation tools will certainly come in handy, as well as some simulation tools.
In addition, such a solution will allow interaction with the different levels of restaking in Solana such as Picasso, Solayer, Jito and others, both on the reskstackers' side and on the operators' side.
Definitely, some kind of conductor is required to make this orchestra play in perfect tune.
How can we summarise these three problems more generally and find a single solution for all of them? Well, we think it's actually quite simple.
Obviously, the solutions to all of these problems depend on the parameters of the nodes, which makes a good telemetry solution a must. We need to collect as much data as possible to make the best decision on restaking funds or delegating jobs to a certain node, as well as building analytics and simulations for node selection.
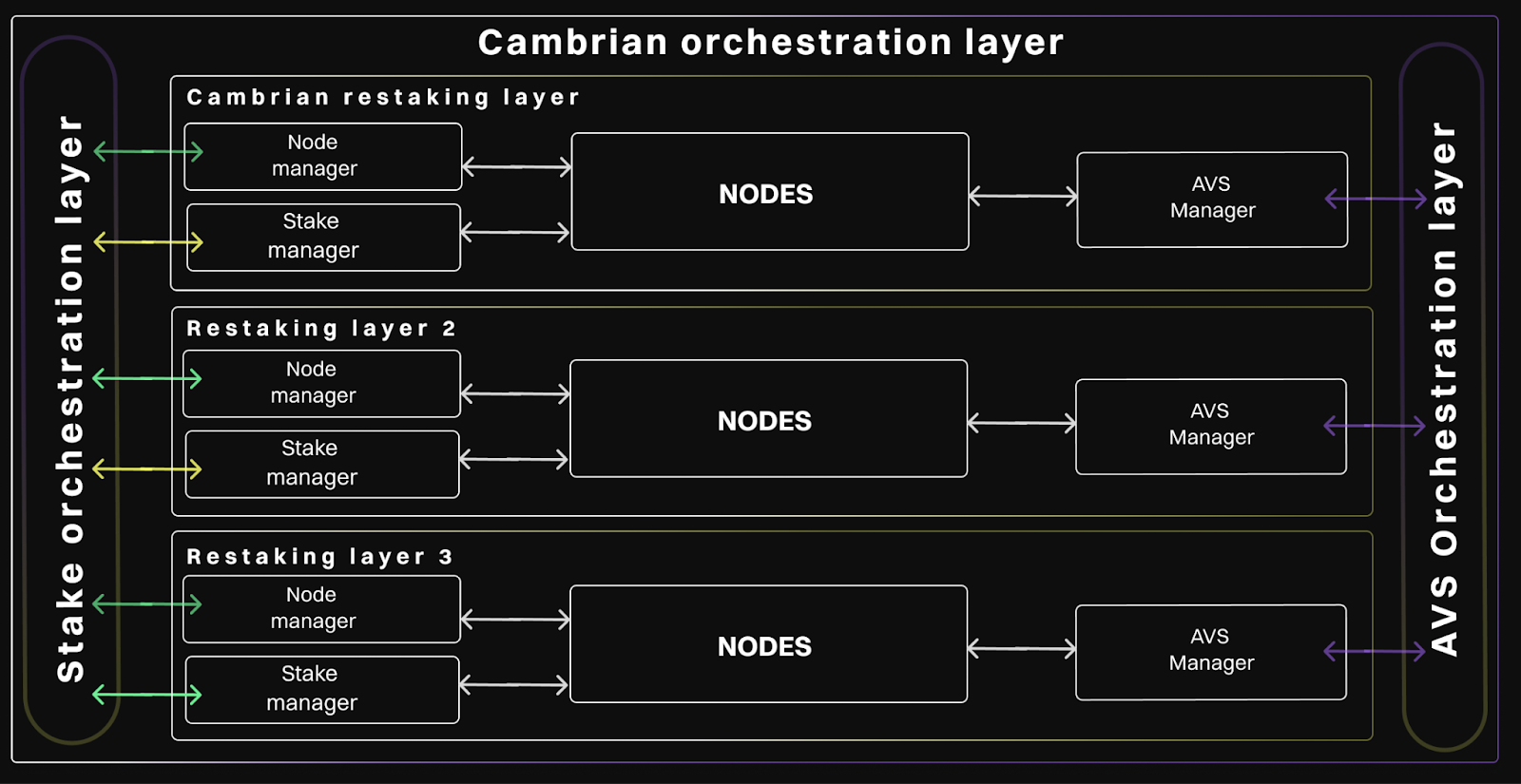
Next, it is safe to assume that all solutions require the same data from all nodes. This data may also contain some aggregated values, such as the total bet between certain nodes, the place of the current node in the list with the most bets, etc. We can consider them as the result of a SQL query (sorry for the technical issues, this will happen again later)
Once we have these query results for all nodes in the system at a given time, we need to find the required distribution of deployments and jobs across these nodes. The logs of this distribution can then be used as analysis tools for the nodes. So how can we find this distribution?
As we have already found out, a worker node can be fully described by a set of values that we collect from it during our system work. The concept of orchestration is quite simple: we introduce a special function that receives this set of parameters and returns a deployment ratio for the given node, or 0/1, to see if a job should be run on a node or not. For now, you can think of this function as a Solana program.
But how are we to know when to invoke this function? This is a difficult question, but we have an answer. We will recalculate the distribution based on trigger events. These can be significant changes in node parameters, changes in AVS jobs, timers and general user events. All these triggers are placed in an asynchronous queue, which is then processed by the event manager, which throttles and groups all the triggers to minimize the workload and send the signal to the AVS orchestration to perform the required calculations.
Subsequently, this AVS performs all the required heavy lifting, is validated and the results are again placed in another asynchronous queue to be processed by the change manager. This program receives the results of the orchestration calculations and transforms them into raw API calls to restaking layers to change their state to match the required state.
Voila! Our orchestra plays perfectly, all is done automatically and everyone is enjoying the music. And all the telemetry from nodes can also be used to build alert systems in case something goes wrong.
This is a top level view of the orchestration solution. And this topic requires further in-depth research and search for answers to the following questions:
How the conductor function should be made. Are they real Solana programs or should they be written in some kind of DSL and be only stored on-chain?
What are those asynchronous queues that we use for calculations? Is it the blockchain itself, or is it something like kafka or zmq?
Where and how do we store nodes’ telemetry? On-chain or off-chain? If off chain then how do we prove it’s validity an authenticity?
About Cambrian
Cambrian is ready to redefine the Web3 landscape and bring the efficiency and innovation of AWS to the decentralized world. Join us on this transformative journey and discover the future of blockchain technology.
Subscribe to Cambrian's official resources and social media to stay up to date on all updates: